Local AI.
No compromises.
Local-first inference engine with a desktop shell, OpenAI-compatible API, MCP tool use, Bankr routing, and Ollama model reuse.
$ npm i -g darksol
Local-first inference engine with a desktop shell, OpenAI-compatible API, MCP tool use, Bankr routing, and Ollama model reuse.
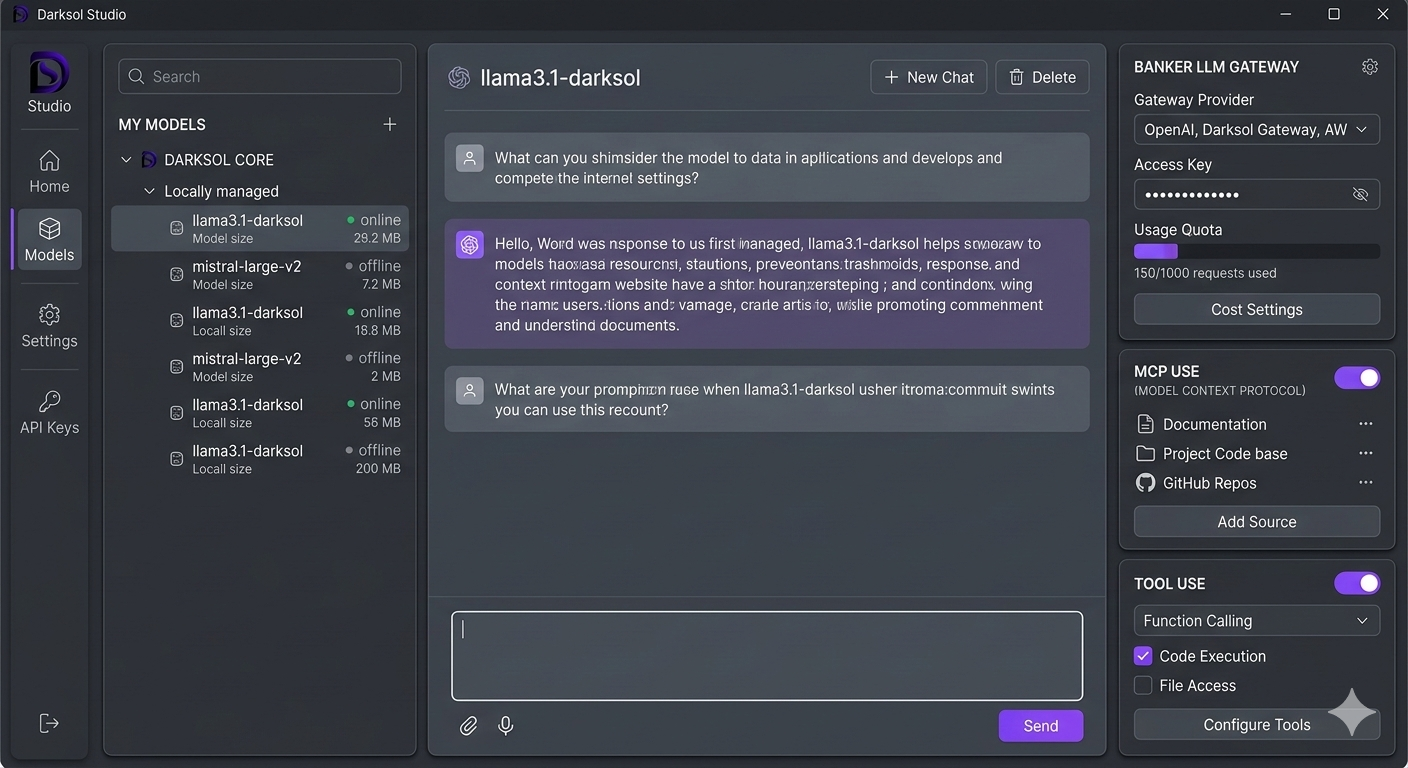
Built for developers and power users who want full control over their AI stack.
Auto-detects GPU, VRAM, CPU cores, and RAM. Optimizes gpu_layers, threads, and context size automatically.
Drop-in replacement. /v1/chat/completions, /v1/completions, /v1/models, /v1/embeddings. SSE streaming built in.
Already have Ollama models? Darksol finds and runs them directly — no re-download, no daemon required.
Browse, search, and pull GGUF models. Hardware-aware fit indicators tell you what runs before you download.
Connect external tools via Model Context Protocol. CoinGecko, DexScreener, Etherscan, DefiLlama — pre-configured.
Route to Bankr cloud models when needed, and connect the local signer for balance checks, transaction sends, and signature flows (beta).
Every local inference is $0.00. Track your usage, tokens processed, and savings vs cloud providers in real time.
Real-time GPU/CPU temperature tracking. Know when your hardware is hot before it throttles your inference.
Enable models to call functions, execute code, and access files. Configurable per-session from the app settings panel.
Free. No account required. Your data never leaves your machine.
All three are strong local-AI options — here’s where each one wins.
Everything works from the command line too.
Local by default. Optional cloud routing only when you choose it.